Learning broad world knowledge directly from raw visual data is a fundamental capability of intelligence. We introduce UniVR, the first investigation into simultaneously learning complex reasoning, fine-grained physical dynamics, and long-term planning from pure visual demonstrations. At its core, UniVR features VR-GRPO, a reinforcement learning paradigm with complementary global and step-level rewards. This approach enforces logical coherence and physical consistency throughout the reasoning process without requiring task-specific heuristics or image-text pairs. To train and evaluate UniVR, we construct VR-X, a large-scale benchmark curated from 16 diverse sources spanning long-horizon manipulation, spatial puzzles, and physical reasoning. It is the first comprehensive suite to assess these heterogeneous capabilities under a purely visual protocol. Remarkably, UniVR achieves up to a 25% improvement on VR-X, and its superior visual reasoning also boosts performance on various multimodal understanding benchmarks. These findings underscore the vast potential of reasoning within visual spaces, with all code, data, and models to be open-sourced for further research.
1. We are the first to explore learning heterogeneous tasks—from long-term planning to general cognitive reasoning—directly in a unified visual space without language supervision.
2. We propose VR-GRPO, a novel RL paradigm featuring Step-Focal rewards that proactively target error-prone reasoning substeps alongside global rewards, significantly improving logical coherence and physical consistency without relying on image-text pairs or task-specific rules.
3. We introduce VR-X, a large-scale benchmark for evaluating diverse tasks in visual space, spanning from fine-grained long-term planning to general reasoning across 16 diverse sources and 1.5M raw samples, to facilitate future research on visual reasoning.
Current AI models primarily derive world knowledge from text, performing reasoning and planning within the textual space. However, text is an abstract representation of the world, unable to fully encompass the rich information of the real visual world, such as complex dynamics, spatial relationships, and underlying physical laws. In contrast, vision serves as the most direct medium for world knowledge and remains the primary source for animals and humans to acquire information. Humans can perform complex reasoning without relying on language by directly simulating task execution and scene transitions in their minds—this constitutes our innate visual reasoning capability.
Recent approaches, such as MLLMs paired with generative models, conveniently leverage pre-existing linguistic strengths, but textual abstractions inherently struggle to capture intricate dynamics and spatial relationships. Their reasoning still remains heavily dependent on text guidance, requiring dense image-text pairs for both training and inference. These limitations drive our core inquiry: How can models utilize raw visual data to boost their visual reasoning capabilities across diverse tasks?

Given an image sequence and an instruction, UniVR models the next-frame distribution using image sequences containing demonstration trajectories across diverse scenarios. Our formulation does not require dense textual reasoning chains, but instead directly models the state transitions and underlying policy dynamics in these trajectories, encouraging the model to reason in visual space. We adopt Emu3.5 as our baseline, a state-of-the-art unified generative model that produces variable-length image sequences using a VQ-VAE-style autoencoder.
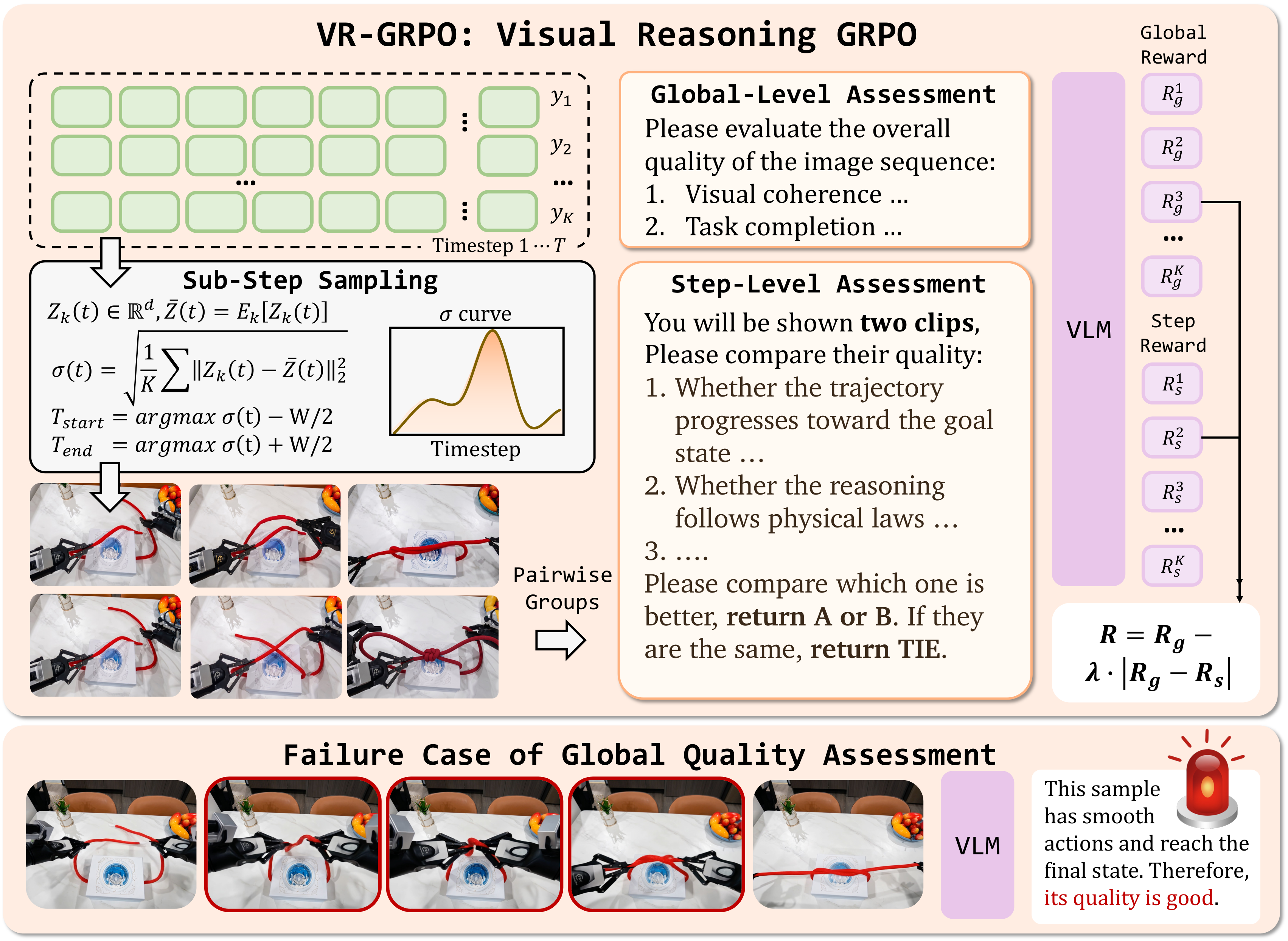
While RL methods like GRPO offer a promising paradigm for performance enhancement, existing methods prioritize visual fidelity over reasoning correctness. We propose VR-GRPO, which integrates two complementary reward signals:
Global Reward (Rg): A VLM evaluator provides holistic assessment of generated sequences for task completion and visual quality.
Step-Focal Reward (Rs): We introduce a step-focal reward designed to identify the most error-prone steps in the reasoning trajectory. By extracting per-frame CLIP embeddings and calculating inter-trajectory variance, we locate the timestep of maximum uncertainty where the model's reasoning paths diverge, then focus the VLM on these critical steps for fine-grained evaluation.
The final reward combines both: Rreason = Rg − λ|Rg − Rs|, preventing the model from taking reasoning shortcuts while maintaining procedural integrity and physical coherence.
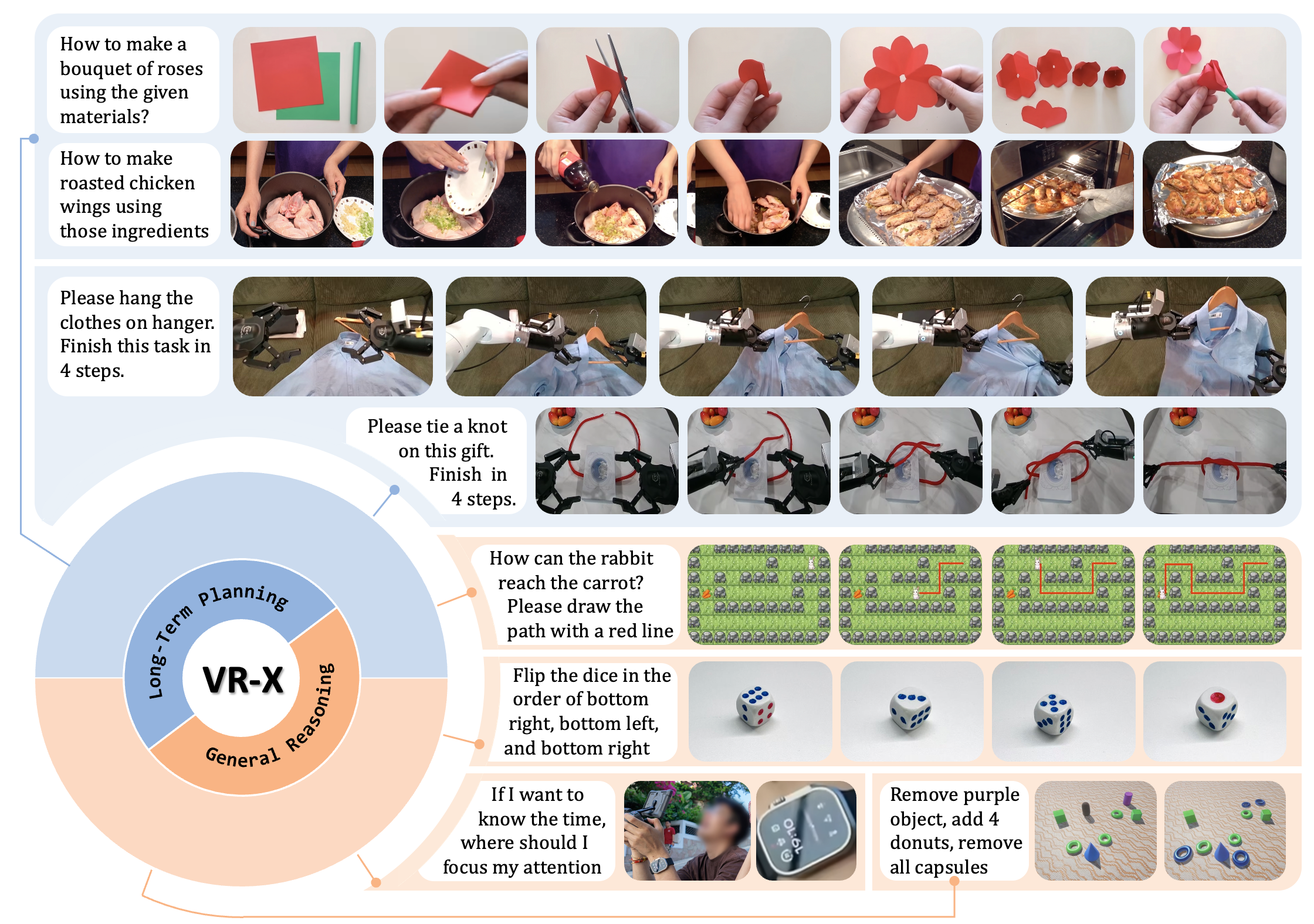
We introduce VR-X, the first large-scale benchmark designed for diverse and heterogeneous visual reasoning. VR-X is curated from 1.5M raw samples across 16 diverse sources (e.g., AgiBot, Action100M, EgoDex, VisualCoT), spanning minute-long planning (robotic manipulation, cooking, handcrafting) to single-step reasoning (mazes, visual search). After rigorous curation, the benchmark contains 310k cold-start training, 3k RL, and 1.8k evaluation samples, all in a unified format: query image, textual instruction, visual reasoning trajectory.
Comparison on VR-X Benchmark
Qwen, Gemini 2.5/3, and GPT-5 are paired with Qwen-image-edit, Nano Banana 1/2, and GPT-image-1.5, respectively.
| Method | Visual Thinking | Guidance | Robot | Editing | Spatial | Puzzle | Search | Overall↑ | JEPA↓ |
|---|---|---|---|---|---|---|---|---|---|
| Large Multimodal Model + T2I Model | |||||||||
| Qwen3-VL-235B | ✗ | 48.2 | 62.8 | 42.1 | 38.2 | 64.1 | 59.8 | 52.5 | 18.08 |
| Qwen3.5-397B | ✗ | 47.0 | 63.2 | 39.8 | 40.4 | 65.6 | 64.5 | 53.4 | 18.64 |
| GPT-5 | ✗ | 68.2 | 64.1 | 58.0 | 49.3 | 64.0 | 77.4 | 63.5 | 12.17 |
| Gemini-2.5-pro | ✗ | 58.4 | 67.9 | 54.0 | 40.5 | 67.7 | 76.3 | 60.8 | 14.39 |
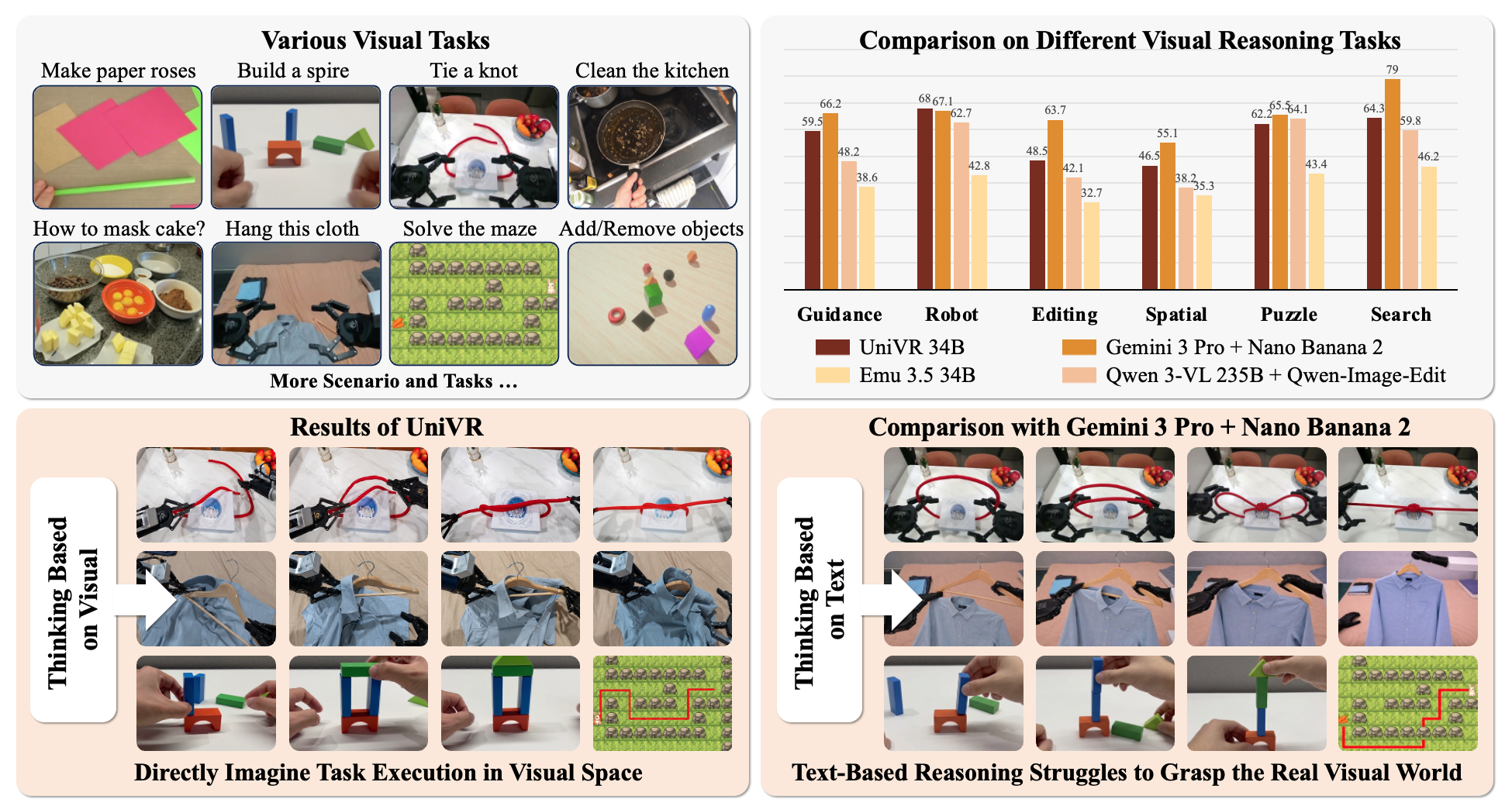
| Gemini-3-pro | ✗ | 66.2 | 67.1 | 63.7 | 55.1 | 65.5 | 79.0 | 66.1 | 11.07 |
| Unified Generation Model | |||||||||
| Janus-pro | ✗ | 9.2 | 18.2 | 5.4 | 10.2 | 27.1 | 21.5 | 15.3 | 68.79 |
| Show-o2 | ✗ | 15.1 | 22.5 | 13.0 | 17.1 | 29.4 | 35.8 | 22.2 | 59.93 |
| Bagel | ✗ | 25.2 | 34.7 | 20.9 | 21.3 | 35.1 | 47.7 | 30.8 | 40.88 |
| OmniGen2 | ✗ | 20.4 | 29.4 | 15.2 | 16.9 | 30.5 | 42.1 | 25.8 | 47.09 |
| Emu3.5 | ✗ | 38.6 | 42.8 | 32.7 | 35.3 | 43.4 | 46.2 | 39.8 | 33.62 |
| UniVR | ✓ | 59.5 | 68.0 | 48.5 | 46.5 | 62.2 | 64.3 | 58.2 | 13.01 |
| Δ v.s. Emu3.5 | ↑20.9 | ↑25.2 | ↑15.8 | ↑11.2 | ↑18.8 | ↑18.1 | ↑18.4 | ↓20.61 | |
UniVR significantly boosts visual reasoning capabilities without compromising the foundational strengths of the base model (Emu3.5). With only 34B parameters, UniVR approaches the performance of the Gemini 3 Pro + Nano Banana 2 pipeline and even surpasses Gemini 3 in long-horizon manipulation tasks. Among unified generation models, UniVR achieves a remarkable +18.4 overall improvement over Emu3.5.
Results on Multimodal Understanding Benchmarks
| Method | MMMU | MME(P) | MME(C) | MMBench | MathVista | MM-Vet |
|---|---|---|---|---|---|---|
| Emu 3.5 | 0.292 | 781.1 | 324.6 | 0.183 | 41.7 | 28.0 |
| Text-only training | 0.290 | 782.0 | 323.4 | 0.199 | 40.8 | 28.3 |
| UniVR | 0.337 | 799.3 | 338.5 | 0.198 | 44.0 | 35.6 |
| Δ v.s. Emu3.5 | ↑0.045 | ↑18.2 | ↑13.9 | ↑0.015 | ↑2.3 | ↑7.6 |
Enhanced visual reasoning serves as a powerful complement to textual supervision, effectively bolstering overall multimodal comprehension. Training solely on textual reasoning chains yields negligible gains, while UniVR's visual reasoning paradigm leads to significant improvements across all six benchmarks.

@article{ren2026univr,
title={UniVR: Thinking in Visual Space for Unified Visual Reasoning},
author={Zhongwei Ren and Yunchao Wei and Zhao Yao and Guixun Luo and Yao Zhao and Weibo Gong and Xiao Liu and Anran Wang and Xiangtai Li and Xiaojie Jin},
year={2026},
}